Rails Grape Unicorn Nginx API Benchmark
我们将一款 APP 的后端,部署在一台独立的服务器上,部署完毕后,对后端程序进行了并发量测试。 测试的目的是: 在并发请求下,监控后端程序的各项性能参数。 找到后端程序的瓶颈,为接下来的接口优化,以及服务器硬件升级,提供数据支持。
测试环境说明
服务器端配置:单核 CPU,1G 内存,1MB 带宽。 测试电脑:MacBook Pro,OS 10.10.2,i5 4 核处理器,内存 16G。 本次测试均在公司内部进行,WIFI 使用 work_5G。 由于使用 IP 和 Port 直接请求,响应速度会比走域名解析稍微快一些。 每次并发测试,均持续 60 秒,间隔 3~5 分钟测试一组。
测试接口
APP 首页接口:http://IP:Port/homepages 访问频率最高,后端逻辑涉及:框架内部逻辑(HTTP,Route,Controller),Databse(Model,SQL) 和 Cache。 Hello world 接口:http://IP:Port/homepages/hello 只涉及框架内部逻辑。
并发测试结果
抽取几组比较有代表性的数据,汇总截图如下:
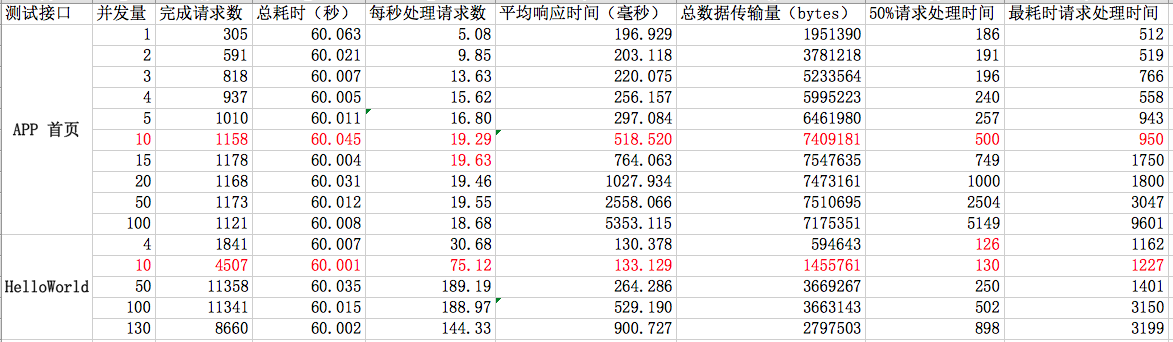
首页接口分析
并发量为 10 时,50%的请求在 500 毫秒以内处理完成,最耗时请求小于 1000 毫秒,用户还能够忍受。
后端程序,每秒处理请求数的最大值,与每次请求的处理时间,以及后端的 worker 数有关。 理论上,每个 worker 瞬时只能处理一个请求。遇到耗时的请求,将阻塞后续请求。
并发数超过 130 时,后端程序在成功处理 120 至 200个请求后,将停止响应请求。 AB 测试终止,错误信息为:apr_socket_recv: Connection reset by peer (54)
统计工具检测到,首页接口的请求处理情况,如下图:
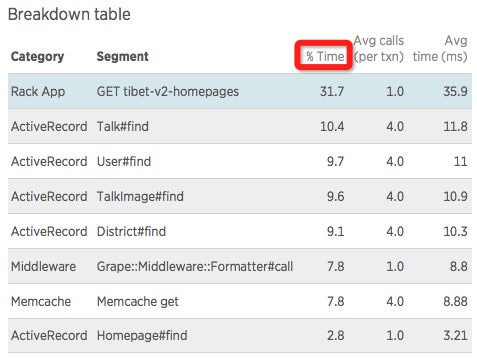
由统计数据可知,请求平均耗时 113 毫秒。
最耗时部分为:ActiveRecord 即 Model + SQL 部分,占比 41.8%。后续将着重优化,增加读数据 Cache。
其次,是框架处理 HTTP 请求和响应部分 Rack,占比:31.7%。
HelloWorld 接口情况
从测试数据上看,在并发量为 10 时,平均响应时间为 133 毫秒。
可见框架内部处理 HTTP 请求的性能,还是非常慢的。
统计数据,如下图:
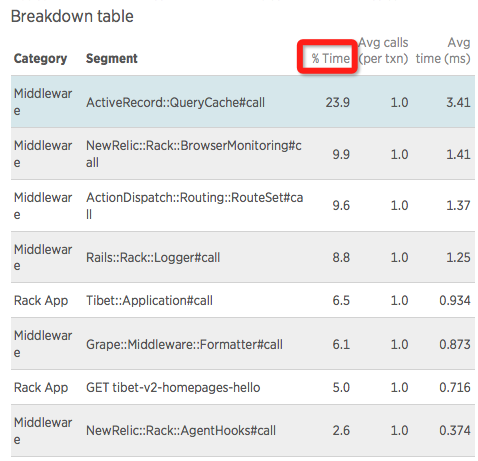
请求耗时比例如下:
QueryCache:23.9%,Rails 框架特性,实则为了加速请求而设计
NewRelic: 12.5%,性能监控逻辑,后期移除
Routing:10.18%,HTTP 路由匹配和分发,后续将研究优化
Rack::Logger: 8.8%,日志部分
后端整体处理耗时比例
HTTP:9.4% Ruby:34.4% Database:46.8% Cache:9.4%Ruby + Database,占比超过 80%,因此,是将要着重优化的环节。
在密集的请求测试下,服务器端的硬件数据统计如下:
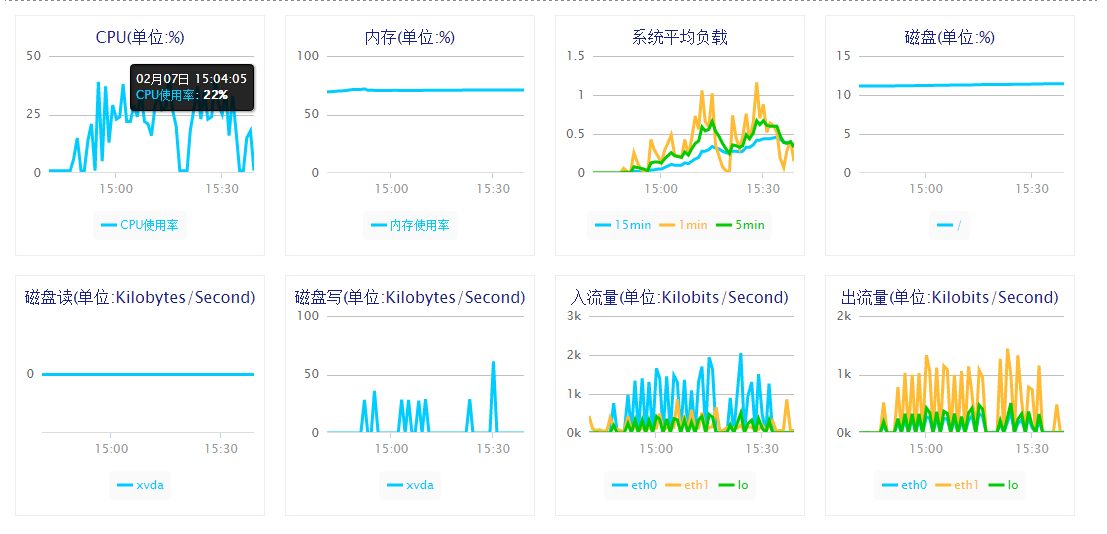
CPU 监控数据:CPU 使用率在 25%,负载接近单核的饱和运行。
带宽 监控数据:入流量和出流量稳定在 1000 Kb/s,峰值均超过 1MB/s
内存 监控数据:平稳状态下使用率:62%,峰值:86%
【备注】阿里云的监控数据,与 zabbix 的统计,稍微有些出入。感觉阿里云界面好看,zabbix 的数据更靠谱!
阶段一测试结论
1. Ruby 非常耗内存:4 个 instances(1 Master + 4 Workers),占用 640 MB 的内存。 2. Rails + Grape 的 Web 架构,框架内部处理 HTTP 请求比较慢。 3. 访问量大的情况下,内存和带宽在 Ruby 的环境下,最容易成为瓶颈
阶段一改进计划
1. 升级内存至 2G; 2. 参照 NewRelic 的监控数据,优化最耗时接口(大于 500ms 的接口); 3. 优化缓存处理机制,增加接口读数据的缓存。
长远规划
1. 升级 Ruby 的版本,提升 GC 的处理性能; 2. 寻找替换 Unicorn 的 Web Server,要支持:低内存消耗、高并行处理; 3. 调整 Rails/Grape 内部处理 HTTP 机制,提升处理速度; 4. 升级服务器硬件配置,增加负载均衡。
2015-02-09
