Hacker Rank Programming Contest For Online Interview
本文讲解巧妙的使用 Hacker Rank在线编程竞赛的平台,创建竞赛项目,让面试人员在线完成竞赛题。 从而实现对面试者实践动手能力、逻辑思维能力、算法能力、编码命名习惯的考察。
Hacker Rank 平台介绍
HackerRank 平台是为了帮助程序员提高技能,举行过数以千计的编程挑战赛。成千上万来自世界各国的程序员参加过这些挑战赛,使用的语言和技能也五花八门,从 Python 到算法、从安全到分布式系统都有涉及。社区已经拥有 150 万程序员用户,还在持续增长。
Hacker Rank 平台提供多种编程领域的挑战题,包含:算法、数据结构、数学、AI 人工智能、数据库等。
程序员自由选择领域以及解题使用的语言,统计数据显示,遥遥领先的是算法,得到了近 40%的程序员青睐。
这个领域的挑战赛包括数据挖掘、实时工程、关键字搜索和一些基础逻辑项目。
在算法领域,程序员可以便捷地选用任何他们想要选用的语言,同时,在编程类的面试中,算法也很重要,这或许是很多程序员会选择练习算法的原因。
再来看看第二名和第三名, Java 领域 和数据架构的比例分别都占到了接近 10%。分布系统和安全的占比最低。
Hacker Rank 官方梳理了在各种挑战赛中各国程序员的成绩,基于数据说明各国的实力,主要根据编程的速度和精度加权对程序员打分和排名。
结果毫无悬念,中国的分数最高。
将中国的分数作为 100 的基准分,则俄罗斯的分数为 99.9 ,两国仅相差 0.01 。另外,波兰和瑞士也以 98 的高分进入前列,榜单尾巴上的巴基斯坦得分仅为 57.4 。
印度和美国为全世界贡献了最多的程序员,但没有进入榜单的前 25 ,只分别以 76 和 78 的分数排名 31 和 28 。
不同国家的程序员对选择的编程语言也有偏好。总的来说,全世界的程序员选用 Java 的比例都要高于其它语言。
只有少数的例外:如马来西亚和巴基斯坦的程序员更喜欢 C++,台湾的程序员更喜欢 Python,印度人更喜欢 C#,墨西哥程序员喜欢用 Ruby。
注册账号,创建竞赛项目
访问 Hacker Rank 官网,输入邮箱即可注册。
注册完成之后,在个人的管理控制台,可以创建 contest 竞赛,如图: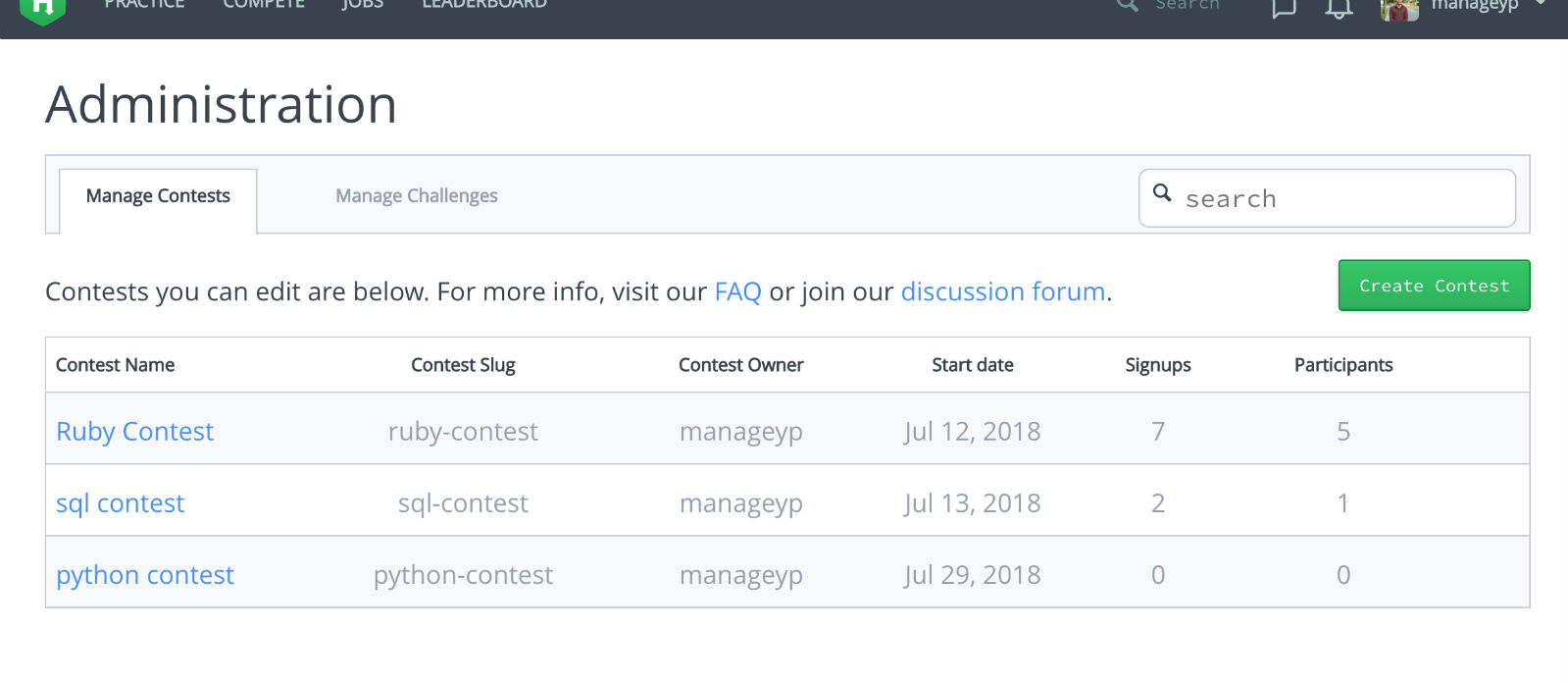 可以设置竞赛的名称,访问 URL,竞赛起始日期等。
可以设置竞赛的名称,访问 URL,竞赛起始日期等。
设置竞赛题
竞赛 contest 设置完成之后,开始设置竞赛题。可以从平台竞赛题库内选择,也可以自己创建试题。
我们从题库内选择的试题相对简单。如图: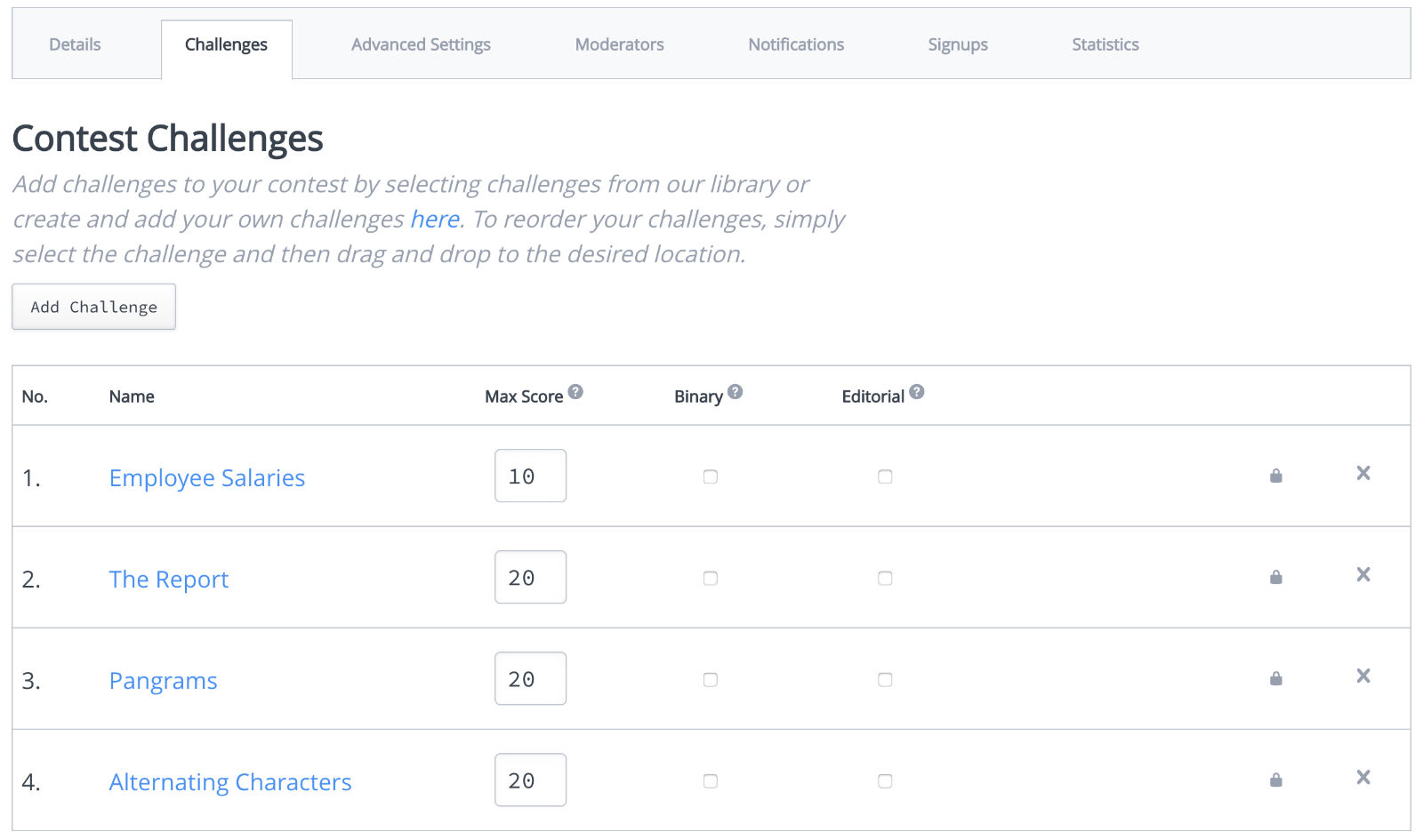 一般面试题数量控制在 5 题以内,完成时间在 2 个小时以内。
一般面试题数量控制在 5 题以内,完成时间在 2 个小时以内。
面试者在线答题
访问竞赛 URL,输入昵称和邮箱,开始解决竞赛题。如图: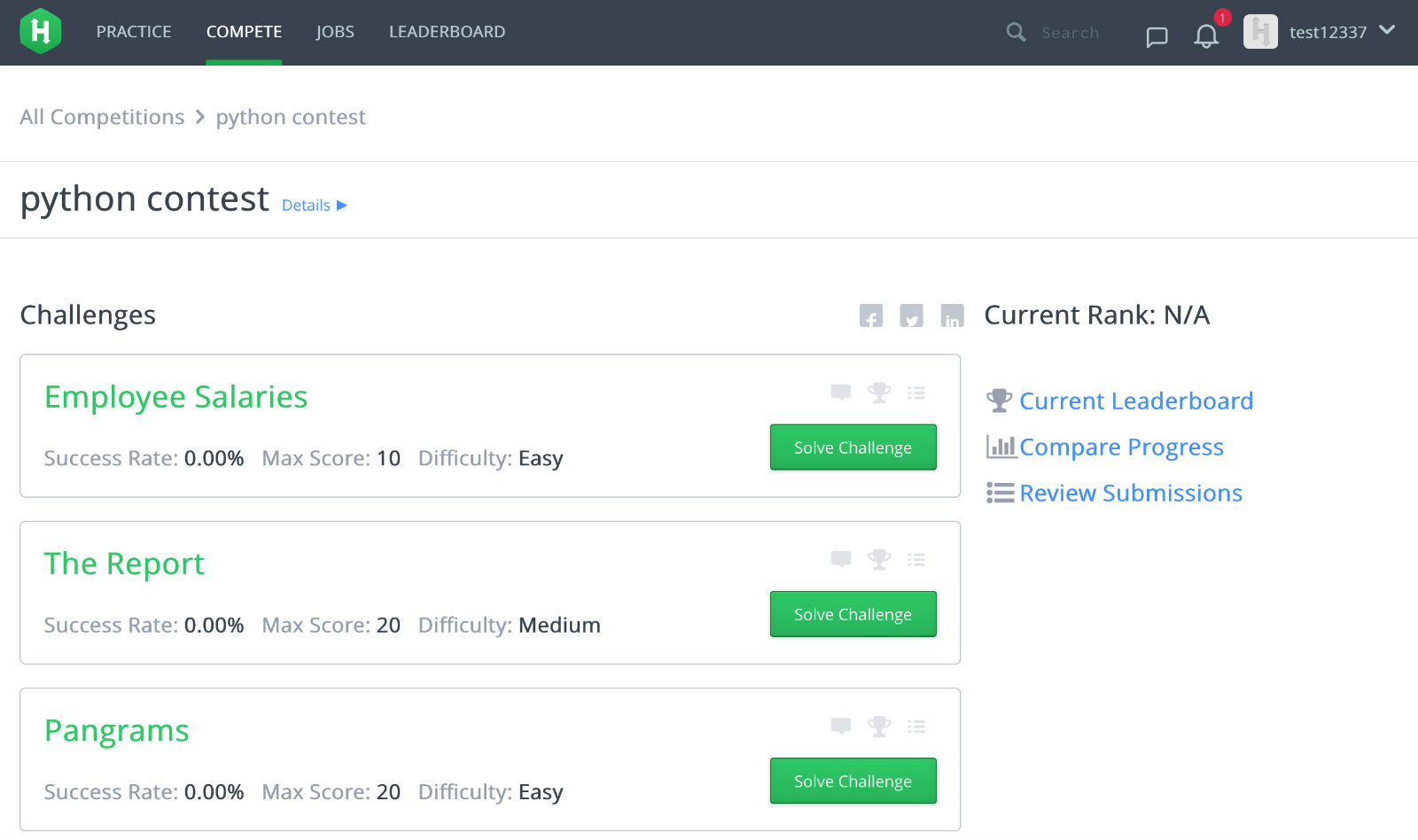
每做一道题,都需要 Run code,如果代码运行后,所有的 Test case 都通过了,说明这道题做对了。反之,则有未知的 Bug 存在。题目完成之后,面试者可以 Submit 提交代码,以待审查。如图: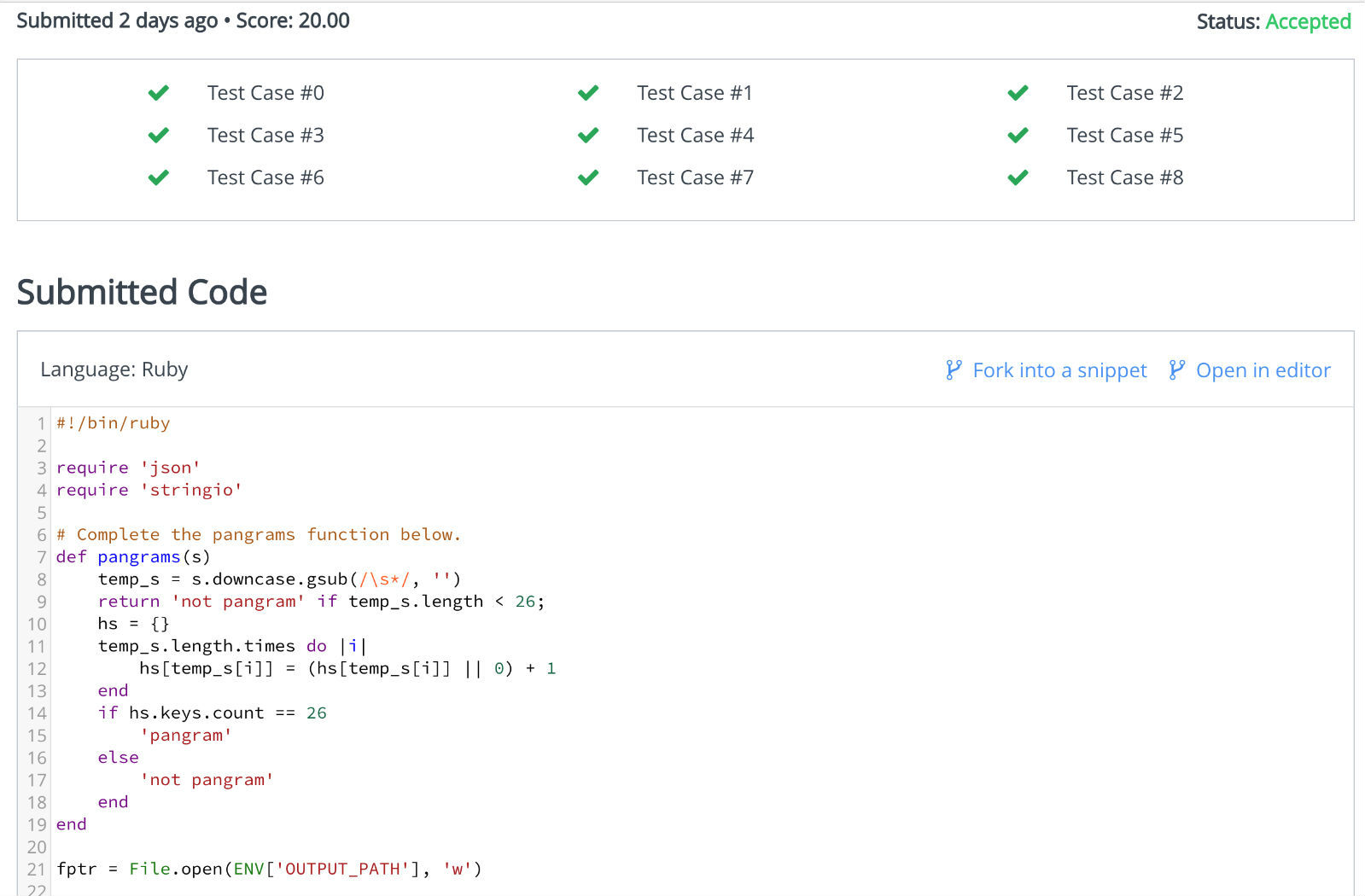
系统从开始时,即记录了每一道题的解题时间,以及提交的代码。
如图: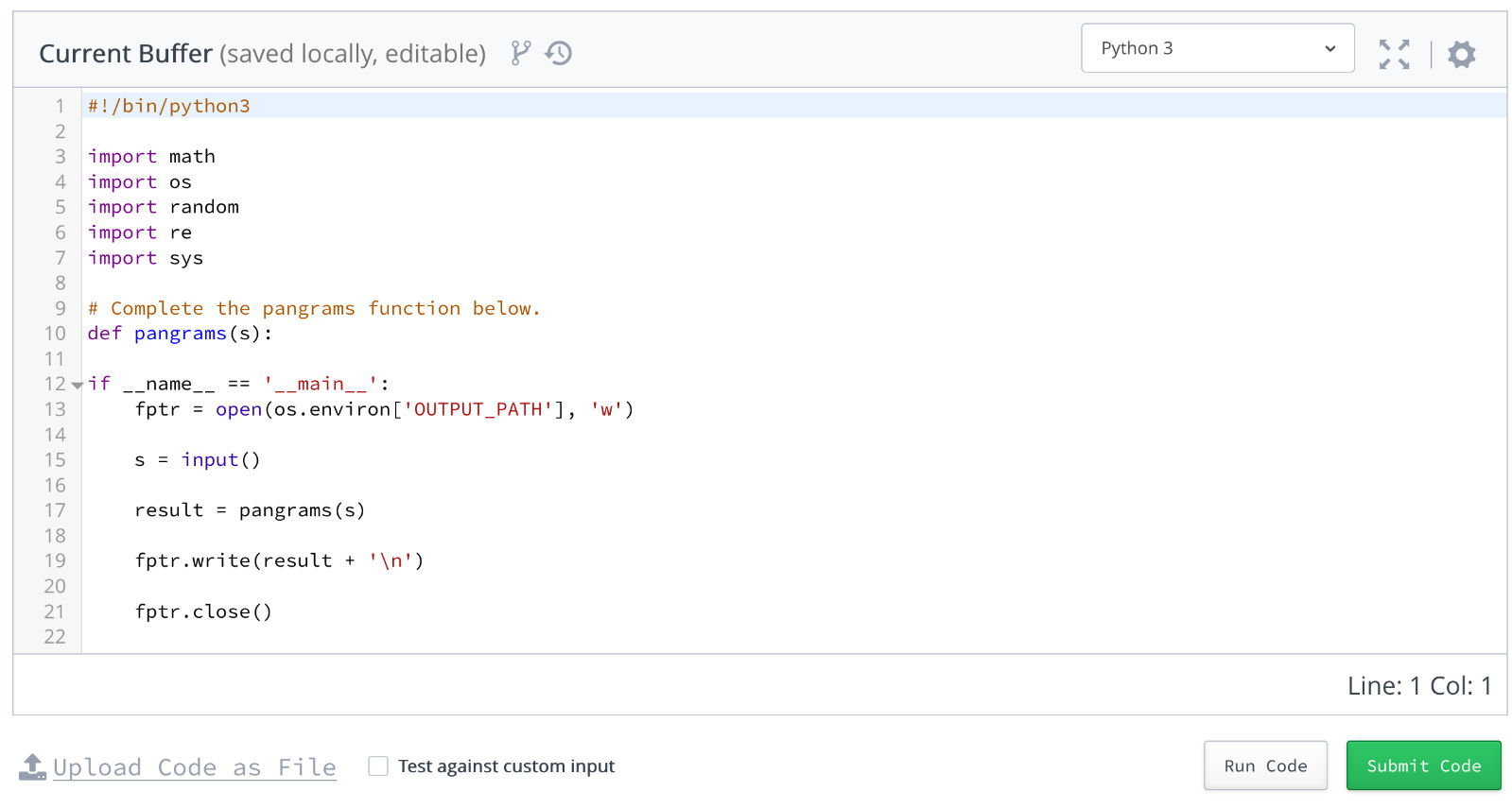
在线审阅答题结果
创建竞赛题的 Owner 可以在线查看做题的统计数据,如图: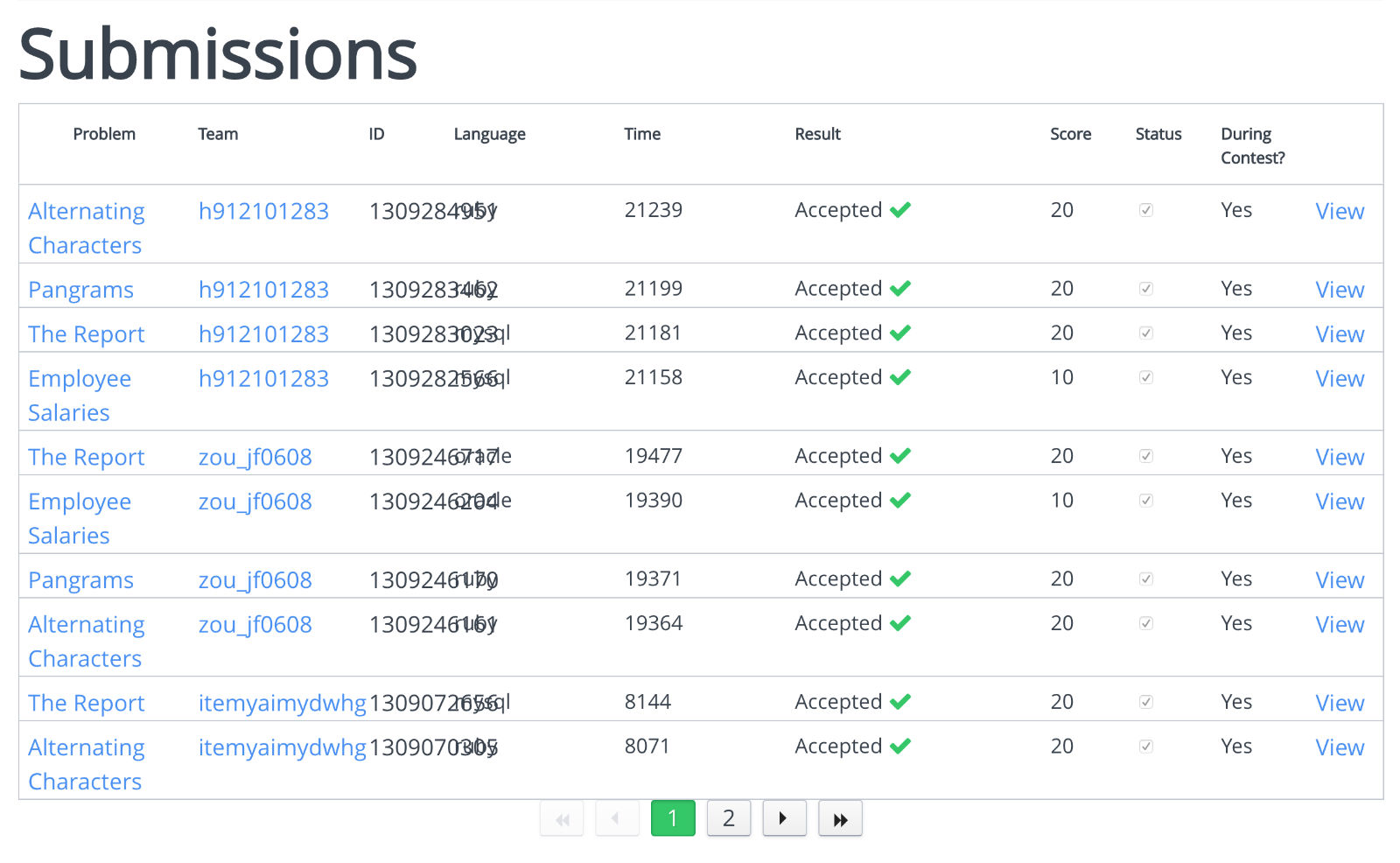
每一位面试人员,解题的耗时、提交的代码,代码的命名规范等,都一目了然。
可以全方位的考察,应聘人员的技术水平。
对于解题优秀的人员,再安排进一步的面试。非常节省面试时间,并且能够高效的选出编程高手。